
Методика навчання моделей комп’ютерного зору на базі зібраних та розмічених даних
Використання згорткових нейронних мереж для вирішення подібних задач зазвичай дозволяє досягти більшої точності у виявленні кратерів [2]. Проведені експерименти включали дослідження таких архітектур як YOLO (You Only Look Once), Faster R-CNN (із різними базовими моделями) та SSD (Single Shot Detector).
Розглянемо базову архітектуру YOLOv5, як основну модель, що використовувалась для визначення вирв на супутникових зображеннях. Загалом архітектура складається із трьох компонент (рис. 4):
- Основа або «Хребет» (Backbone) — ця частина моделі складається із конволюційних шарів та відповідає за формування набору ознак для детекції об’єктів на зображенні
- Мережа об’єднання ознак (Neck) – ця частина моделі трансформує отримані ознаки в три карти ознак (P3-P5, рис. 4)
- Предиктивні шари (Head) – в цій частині моделі вже відбувається визначення границь обїектів та їх класів.

Рис. 4 Загальна архітектура моделі YOLOv5
Загальна процедура обробки зображення відбувається наступним чином: зображення проходить через вхідний шар (input), де відбувається його масштабування та підготовка і надсилається до шарів Основи, де відбувається формування ознак різного розміру.
Отримані карти ознак різного розміру за допомогою мережі об'єднання ознак (neck) об'єднуються у три карти ознак P3, P4 та P5 (в YOLOv5 розміри виражені у величинах 80×80, 40×40 та 20×20) для виявлення малих, середніх і великих об'єктів на зображенні відповідно. Після того, три карти ознак надсилаються на предиктивні шари (head), де обчислюються оцінки впевненості моделі та межі знайдених кратерів для кожного пікселя в карті ознак за допомогою попередньо визначеного анкора, щоб отримати багатовимірний масив, що включає клас об'єкта, довіру до класу, координати рамки, ширину та висоту.
Встановивши відповідні порогові значення (confthreshold, objthreshold) для фільтрації непотрібної інформації в масиві та виконавши процес ненадмірного подавлення (NMS), можна отримати фінальну інформацію про виявлення.
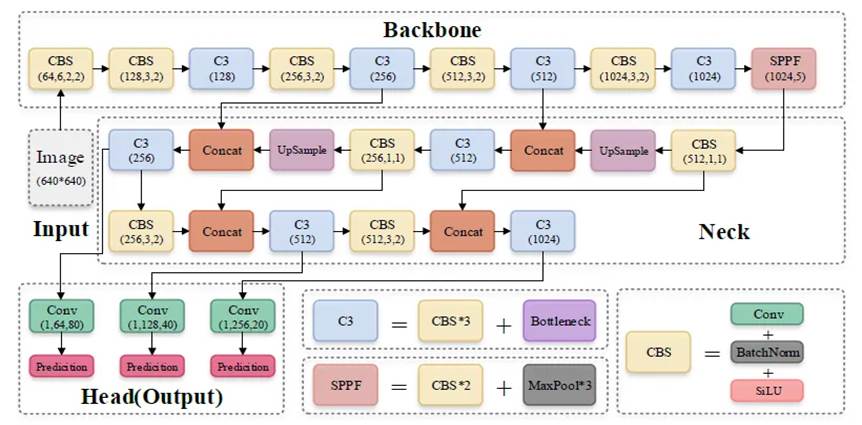
Більш детальна структура шарів моделі YOLOv5 представлена на рис. 5

Рис. 5. Структура шарів моделі YOLOv5
Як можна побачити із рис 5, базовим компонентом архітектури є додаванні кількох модулів CBS (Convolution + BatchNorm + SiLU) та модулів C3, і на завершення підключається один модуль SPPF.
Модулі CBS у поєднанні із модулями C3 сприяють формуванню ознак, тоді як модуль SPPF підвищує здатність основної структури до вираження ознак.
Додатково YOLOv5 використовує методи FPN та PAN для підготовки карти ознак. Основна ідея FPN полягає в збільшенні виходу карти ознак (C3, C4 та C5), створеної за допомогою кількох операцій зменшення розміру за допомогою згорток з мережі видобутку ознак, для отримання кількох нових карт ознак (P3, P4 та P5), призначених для виявлення об’єктів різних розмірів (рис. 6).

Рис. 6 Модифікації мережі об’єднання ознак (Neck)
Останні, предиктивні шари (Head) моделі вже відповідають за визначення границь об’єктів та їх класів.
В цій частині відбувається визначення центрів та розмірів об’єктів. При цьому значення координат верхнього лівого кута зображення встановлюється на (0, 0), а правого нижнього — (1, 1). Координати центрів, висоти та ширини об’єктів визначаються у відносних значеннях. Наприклад центр зображення відповідатиме координатам (0.5, 0.5)
Для навчання моделі та підбору гіперпараметрів використовувались наступні стратегії:
Підготовка та аугментація даних — в межах цієї стратегії ми використовували дані різної роздільної здатності (zoom 17, zoom 18, змішані дані); різні підходи до аугментації даних (повороти, відображення, зміна контрасту, яскравості, насиченості кольорів, перемішування сегментів зображень, масштабування, тощо).
Підготовка та валідація міток — в межах цієї стратегії ми валідували розміри та положення міток, видаляли замалі мітки, які не мали практичної цінності та не впливали суттєво на загальну площу уражену вирвами.
Зміна параметрів голови моделі, зокрема перехід до анкерів із більш збалансованим відношенням сторін, що відповідає природі вирв, які зазвичай мають майже квадратну форму.
Зміна розміру моделі — в межах цієї стратегії при проведенні експериментів щодо детекції вирв використовувались наступні версії архітектури моделі YOLOv5:
YOLOv5n - ця модель має 40 шарів та 1.9 мільйона параметрів, для дотренування використовувалась модель, яка вже була навчена на даних по місячним кратерам, але донавчання моделі на зібраних даних приводило до перенавчання, що свідчило про недостатню складність моделі для цієї задачі.
YOLOv5s – ця модель має 50 шарів та близько 7.2 мільйона параметрів. Вона показала більшу точність та достатню швидкість навчання.
YOLOv5m – яка має 66 шарів та близько 21.6 мільйона параметрів. Ця версія дозволила отримати найкращі результати з точки зору точності із достатньою швидкодією.

YOLOv5l – незважаючи на те, що ця модель більш складна точність отриманих результатів дещо впала, при цьому зниження точності спостерігалось як в процесі тренування так і валідації, що свідчить про надмірну складність моделі для зібраних даних, її гіршу спроможність навчатися на них та необхідність розширення наборів даних та їх варіабельності для отримання кращих результатів.Виходячи із отриманих результатів використання найбільш складної моделі YOLOv5x вбачається недоцільним для зібраних даних.
Базові налаштування та приклад застосування моделі YOLOv5m представлено на рис. 7.

Рис. 7 Налаштування та приклад застосування моделі YOLOv5m
Попередній розділ (Можливості адаптації(трансфертне навчання) на прикладі моделі PYCDA)
Наступний розділ (Особливості застосування евристичних алгоритмів для детекції контурів)