
Програмна реалізація процедури оптимізації гіперпараметрів
Для подальшої оптимізації гіперпараметрів було застосовано бібліотеку Optuna, програмну платформу для автоматичної оптимізації гіперпараметрів, спеціально розроблену для машинного навчання. Вона має імперативний інтерфейс програмування, що базується на принципі "визначити під час виконання". Завдяки розробленому API, що працює за принципом "визначити під час виконання", код, написаний за допомогою Optuna, має високу модульність, а користувач Optuna може динамічно створювати простори пошуку для гіперпараметрів.
При цьому підтримуються різноманітні алгоритми формування вибірки які ефективно звужують простір пошуку, використовуючи записи запропонованих значень параметрів і оцінених значень цілей, що веде до оптимального простору пошуку, який в кінцевому рахунку дозволяє отримати оптимальні значення параметрів.
Серед базових алгоритмів пошуку, що підтримує Optuna варто виділити наступні:
- Градієнтний пошук, реалізований у GridSampler
- Випадковий пошук, реалізований у RandomSampler
- Алгоритм деревоподібної Парзена, реалізований у TPESampler
- Алгоритм на основі CMA-ES, реалізований у CmaEsSampler
- Алгоритм на основі гаусових процесів, реалізований у GPSampler
- Алгоритм для частково фіксованих параметрів, реалізований у PartialFixedSampler
- Алгоритм недомінованого сортування генетичних алгоритмів II, реалізований у NSGAIISampler
- Алгоритм вибірки квазі-Монте-Карло, реалізований у QMCSampler
Процедура пошуку гіперпараметрів виконувалась ітеративно в декілька етапів на кожному з яких відтворювався експеримент, який включав в себе від 100 повторень, які були спрямовані на пошук оптимального значення цільової функції, або досліджуваної метрики (див. рис. 10).
На кожній ітерації метрика розраховувалась виходячи із сформульованих прогнозів та фактичних значень (блок metric_eval на рис. 10).
В свою чергу прогнози визначались в середині блоку make_predictions, який в залежності від значень досліджуваних гіперпараметрів ідентифікував кола на низці зображень, що використовувались для детекції вирв.
Після цього виходячи із координат центрів та радіусів визначених кіл розраховувались відповідні bounding box-и, які в свою чергу зіставлялись із наявними даними щодо розмітки зображень. У випадках, коли метрика IoU (Intersection over Union) була більша за 0.5, ідентифікована вирва вважалась корректно ідентифікованою. Всі запропоновані кола, для яких не було відповідних реальних вирв відносились до помилково позитивних, а всі реальні вирви на зображені, які не мали відповідних ідентифікованих кіл відносились до помилково-негативних.
Таким чином, в межах кожного повторення опрацьовувались всі наявні зображення і розраховувались базові метрики повноти та точності алгоритму детеції вирв.

Рис. 10 Процедура оптимізації гіперпараметрів
На першому етапі експерименту всі параметри досліджувались в довільних широких діапазонах, переважно орієнтуючись на рекомендовані в літературі типові значення параметрів і експериментально встановлені границі змін, які давали візуально контрольовані зміни в детекцій вирв.
За результатами першого етапу експерименту досліджувались розподіл ефективності відносно окремих значень кожного з параметрів (рис 11), а також впливи комбінацій значень параметрів на результати (рис 12).
Для вибору пар параметрів використовували кореляційний аналіз.

Рис 11. Вплив зміни параметру на значення метрики
При аналізі впливу окремих параметрів на значення метрики особливу увагу треба звертати на ерхні значення діапазону (IQR), оскільки саме вони свідчать про те, що відповідне значення параметру має потенціал для покращення цільової метрики.
При дослідженні парних впливів для розділення значень параметрів використовували сигмоїдні перетворення значень метрики, що дозволило біль чітко розділити погані та перспективні діапазони параметрів алгоритму детекцій вирв (див. рис. 12)

Рис. 12. Дослідження впливу комбінації параметрів на метрику якості алгоритму
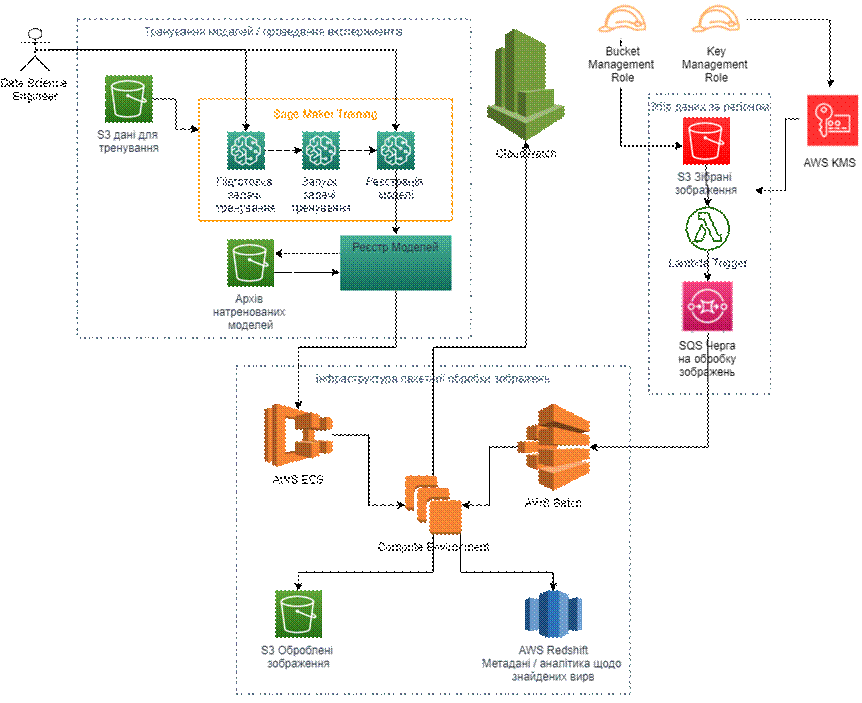
Для практичної реалізацій запропонованого методичного підходу розроблено концептуальну схему архітектури рішення щодо збору, тренування моделей та обробкою зображень на платформі AWS (рис. 13).

Рис 13. Схема архітектури рішення щодо збору, тренування моделей та обробки зображень на платформі AWS
Ключовими особливостями цієї схеми є забезпечення вибіркового доступу та захисту даних за рахунок використання AWS KMS. Використання KMS для керування ключами, також забезпечуює безпеку даних. Застосування сервісів S3 для зберігання та обробки зображень. Для запуску процедур збору та підготовки даних передбачено застосування AWS Lambda, яка використовує тригери для автоматизації відповідних процесів. Тренування, збереження, формування реєстру моделей передбачає використання S3 для зберігання результатів тренування і налаштувань моделей. В цьому компоненті застосування AWS Lambda забезпечує автоматизацію, а також резервне копіювання моделей в Реєстр Моделей. Використання AWS Redshift для аналітики щодо оброблених зображень.
Запропонована архітектура підкреслює інтеграцію різних AWS сервісів для забезпечення ефективного тренування моделей та обробки даних.
Попередній розділ (Особливості застосування евристичних алгоритмів для детекції контурів)
Наступний розділ (Оцінка ресурсів для рекультивації деградованих територій)